
Tensorflow 시작하기 8 (성능 향상-학습 데이터 증가)
사용 버전: Python 3.7.6, Tensorflow 2.1.0
이번 시간에는 간단한 방법으로 성능을 향상시키는 방법을 알아보겠습니다.
그전에 몇 프로의 순위로 뽑힌 건지 확인해 봅시다.
함수를 만듭니다.
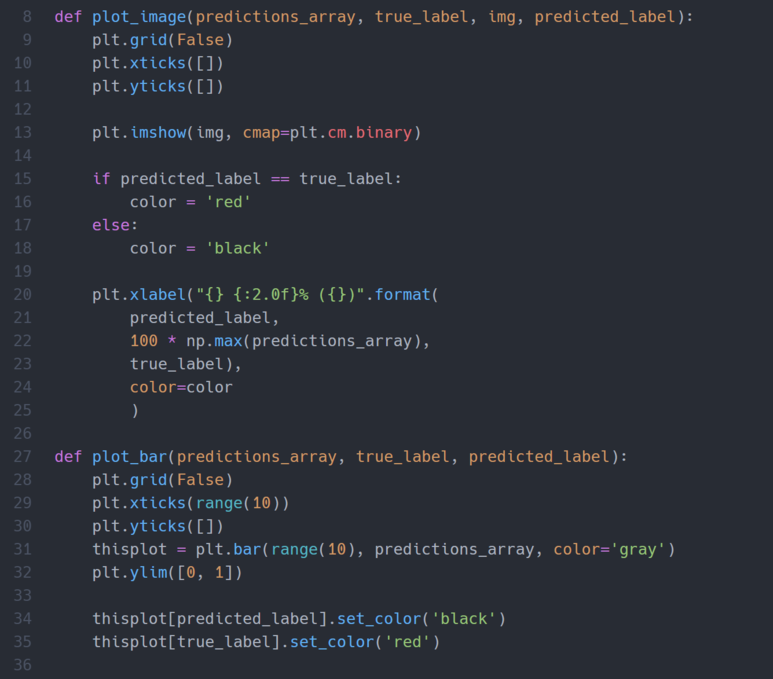
그래프를 그려줍니다.

실행해 줍니다.

예측한 것은 검은색, 정답은 빨간색 그래프입니다. 그리고 그림 밑의 빨간색 주석이 달린 것이 예측과 정답이 맞는 그림입니다.
이제, 우리는 여기에 약간의 코드를 수정하여 성능을 향상시켜보겠습니다.
요즘은 random forest나 ensemble 기법을 많이 사용하는 것 같습니다.
저는 아직 공부를 못해서 기초적인 기법에 대해서 다루겠습니다.
성능을 향상시키는 방법으로는 크게 5 가지 정도가 있습니다.
1. 학습 데이터양을 늘린다.
2. 학습 반복량을 증가한다.
3. 배치를 사용한다.
4. 셔플을 사용한다.
5. 히든 레이어를 추가한다.
학습 데이터의 양, 학습 반복량, 배치, 셔플, 히든 레이어 추가에 대해서 다루겠습니다.
- 학습 데이터의 양이 늘어나면, 학습을 하는데 좀 더 많은 경우를 볼 수 있어서 성능이 향상됩니다.
- 학습 반복량(epoch)을 증가해 주면 학습을 반복적으로 하게 되어, 성능이 좋아집니다. 하지만, 너무 오래 반복하게 되면, 본 것만 맞추게 되어 성능이 떨어집니다.
- 배치(batch)를 사용하면, 전체 데이터를 가지고 학습을 진행하는 것이 아니라, 정해진 크기들끼리의 기울기 값을 사용하여, 전체 기울기를 찾아가게 됩니다.
- 셔플(shuffle)을 사용하게 되면, 학습 데이터 순서에 인공지능이 최적화되는 것을 방지해 줍니다.
- 히든 레이어를 추가하게 되면, 성능이 향상될 수 있습니다. 다만, 너무 많은 층을 사용하면, 오히려 성능이 저하됩니다.
학습 데이터의 양을 늘려보겠습니다. 현재 새로운 데이터를 만드는 것은 시간이 오래 걸리고 쉽지 않으므로, Validation 데이터 셋을 포기하고 전부 Train에 사용하도록 하겠습니다.
그러면, 기존 48,000 개의 학습 데이터가 60,000 개로 증가됩니다.

이제 한 번 확인해봅시다. 좋아졌는지.

별 차이가 없네요.
계속 진행하겠습니다.
끝.
코드:
기획: MNIST 데이터 셋을 이용하여, 손글씨 숫자를 맞추는 AI(인공지능) 만들기
이번 시간에는 간단한 방법으로 성능을 향상시키는 방법을 알아보겠습니다.
그전에 몇 프로의 순위로 뽑힌 건지 확인해 봅시다.
함수를 만듭니다.
그래프를 그려줍니다.
실행해 줍니다.
예측한 것은 검은색, 정답은 빨간색 그래프입니다. 그리고 그림 밑의 빨간색 주석이 달린 것이 예측과 정답이 맞는 그림입니다.
이제, 우리는 여기에 약간의 코드를 수정하여 성능을 향상시켜보겠습니다.
요즘은 random forest나 ensemble 기법을 많이 사용하는 것 같습니다.
저는 아직 공부를 못해서 기초적인 기법에 대해서 다루겠습니다.
성능을 향상시키는 방법으로는 크게 5 가지 정도가 있습니다.
1. 학습 데이터양을 늘린다.
2. 학습 반복량을 증가한다.
3. 배치를 사용한다.
4. 셔플을 사용한다.
5. 히든 레이어를 추가한다.
학습 데이터의 양, 학습 반복량, 배치, 셔플, 히든 레이어 추가에 대해서 다루겠습니다.
- 학습 데이터의 양이 늘어나면, 학습을 하는데 좀 더 많은 경우를 볼 수 있어서 성능이 향상됩니다.
- 학습 반복량(epoch)을 증가해 주면 학습을 반복적으로 하게 되어, 성능이 좋아집니다. 하지만, 너무 오래 반복하게 되면, 본 것만 맞추게 되어 성능이 떨어집니다.
- 배치(batch)를 사용하면, 전체 데이터를 가지고 학습을 진행하는 것이 아니라, 정해진 크기들끼리의 기울기 값을 사용하여, 전체 기울기를 찾아가게 됩니다.
- 셔플(shuffle)을 사용하게 되면, 학습 데이터 순서에 인공지능이 최적화되는 것을 방지해 줍니다.
- 히든 레이어를 추가하게 되면, 성능이 향상될 수 있습니다. 다만, 너무 많은 층을 사용하면, 오히려 성능이 저하됩니다.
학습 데이터의 양을 늘려보겠습니다. 현재 새로운 데이터를 만드는 것은 시간이 오래 걸리고 쉽지 않으므로, Validation 데이터 셋을 포기하고 전부 Train에 사용하도록 하겠습니다.
그러면, 기존 48,000 개의 학습 데이터가 60,000 개로 증가됩니다.
이제 한 번 확인해봅시다. 좋아졌는지.
별 차이가 없네요.
계속 진행하겠습니다.
끝.
코드:
카테고리: Tensorflow, BlackSmith






댓글
댓글 쓰기
궁금한 점은 댓글 달아주세요.
Comment if you have any questions.