
Python bs4.BeautifulSoup()
사용 버전 : Python 3.6.8
사용 프로그램 : Atom 1.35.1 x64
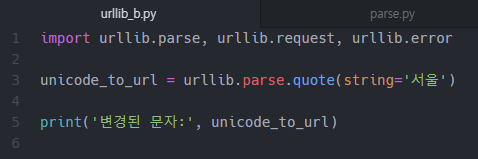
bs4.BeautifulSoup()는 HTML, XML, HTML5등의 데이터를 추출하는데 사용합니다.
'markup' 속성에는 markup 언어 문자열이나, 파일이 들어갑니다.
markup 언어란, 태그를 사용하는 언어를 나타내며, 대표적인 게 HTML(Hypertext Markup Language)입니다.


markup 속성만 사용할 시, BeautifulSoup가 알아서, parser를 찾아서 적용합니다.
물론 잘못된 parser를 사용할 수 있습니다.
parser를 지정해 주는 속성이 feature 속성입니다.
'feature' 속성에는 'lxml', 'lxml-xml', 'html.parser', 'html5lib', 'html', 'html5', 'xml'등이 들어갑니다.
기본 parser 용 내장 library는 'html.parser'입니다.
다른 나머지를 사용하고 싶으시다면, 따로 설치해주셔야 합니다.


보기 좋게 정렬을 해준 것을 알 수 있습니다.
'builder' 속성은 사용하지 않습니다.
'parse_only' 속성을 이용하면, 원하는 태그만 찾고, 표현할 수 있습니다.
parse_only에는 bs4.SoupStrainer()가 들어갑니다.
bs4.SoupStrainer()의 설명은 아래에서 보실 수 있으십니다.
a tag가 있는 부분만 찾아보겠습니다.


'from_encoding' 속성을 이용하면, 불러온 문서를 해독할 encoding을 정해줄 수 있습니다.
생략할 시, 자동으로 찾는데, 잘못된 인코딩으로 해독할 수 있습니다.
인코딩 종류는 여기를 참고하시면 됩니다.
사용 프로그램 : Atom 1.35.1 x64
파이썬 bs4.BeautifulSoup()에 대해서 알아보겠습니다.
괄호 안에는 markup, features, builder, parse_only, from_encoding, exclude_encodings, **kwargs가 들어갑니다.
bs4.BeautifulSoup()는 HTML, XML, HTML5등의 데이터를 추출하는데 사용합니다.
'markup' 속성에는 markup 언어 문자열이나, 파일이 들어갑니다.
markup 언어란, 태그를 사용하는 언어를 나타내며, 대표적인 게 HTML(Hypertext Markup Language)입니다.
markup 속성만 사용할 시, BeautifulSoup가 알아서, parser를 찾아서 적용합니다.
물론 잘못된 parser를 사용할 수 있습니다.
parser를 지정해 주는 속성이 feature 속성입니다.
'feature' 속성에는 'lxml', 'lxml-xml', 'html.parser', 'html5lib', 'html', 'html5', 'xml'등이 들어갑니다.
기본 parser 용 내장 library는 'html.parser'입니다.
다른 나머지를 사용하고 싶으시다면, 따로 설치해주셔야 합니다.
보기 좋게 정렬을 해준 것을 알 수 있습니다.
'builder' 속성은 사용하지 않습니다.
'parse_only' 속성을 이용하면, 원하는 태그만 찾고, 표현할 수 있습니다.
parse_only에는 bs4.SoupStrainer()가 들어갑니다.
bs4.SoupStrainer()의 설명은 아래에서 보실 수 있으십니다.
a tag가 있는 부분만 찾아보겠습니다.
'from_encoding' 속성을 이용하면, 불러온 문서를 해독할 encoding을 정해줄 수 있습니다.
생략할 시, 자동으로 찾는데, 잘못된 인코딩으로 해독할 수 있습니다.
인코딩 종류는 여기를 참고하시면 됩니다.
https://shwoghk14.blogspot.com/2020/08/python-encoding-types.html
한번, iso8859_2 인코딩을 써보겠습니다.


글자가 깨진 것을 볼 수 있습니다.
'exclude_encodings' 속성을 사용하면, 이 인코딩은 제외해라는 뜻입니다.
즉, 무슨 타입인지는 모르지만, 이것만은 절대 아니다 할 때 넣어주면 됩니다.
적지 않으면, BeautifulSoup가 자동으로 설정하며, 잘못 설정될 수도 있습니다.


'kwargs' 속성은 Beautiful Soup 3 사용자를 위해, 변경된 명령어를 알려줍니다.
Beautiful Soup 4에서는 사용되는 명령어가 없습니다.
3에서 사용했던 kwargs로는 'convertEntities', 'markupMassag', 'smartQuotesTo', 'selfClosingTags', 'isHTML'이 있습니다.


위와 같이, 친절히 다른 기능을 사용해라고 알려줍니다.
끝.
카테고리: Python, bs4
한번, iso8859_2 인코딩을 써보겠습니다.
글자가 깨진 것을 볼 수 있습니다.
'exclude_encodings' 속성을 사용하면, 이 인코딩은 제외해라는 뜻입니다.
즉, 무슨 타입인지는 모르지만, 이것만은 절대 아니다 할 때 넣어주면 됩니다.
적지 않으면, BeautifulSoup가 자동으로 설정하며, 잘못 설정될 수도 있습니다.
'kwargs' 속성은 Beautiful Soup 3 사용자를 위해, 변경된 명령어를 알려줍니다.
Beautiful Soup 4에서는 사용되는 명령어가 없습니다.
3에서 사용했던 kwargs로는 'convertEntities', 'markupMassag', 'smartQuotesTo', 'selfClosingTags', 'isHTML'이 있습니다.
위와 같이, 친절히 다른 기능을 사용해라고 알려줍니다.
끝.
카테고리: Python, bs4
.png)






댓글
댓글 쓰기
궁금한 점은 댓글 달아주세요.
Comment if you have any questions.