
Data Analysis 시작하기 6 (추정과 예측)
사용 언어: Python 3.7.9
운영 체제: Windows 11 Home 21H2
지금까지 기본적인 분석을 해보았는데요. 여기서 끝내면 아쉬우니 더 진행해 봅시다. 우리가 데이터를 분석하는 이유는 추정과 예측을 하기 위해서입니다. 저도 정확한 차이는 모르는데요. 추정은 기존의 데이터 범위에서 없는 자료를 분석해서 비어있는 공간을 채우는 것이고 예측은 기존 데이터의 범위를 벗어난 부분을 채우는 것이라고 저는 그냥 이해했는데요. 뭐 똑같은 거 아니냐 할 수 있는데 저도 모릅니다. 그냥 넘어가도록 하죠 헤헤.
LinearRegression을 쓰거나, RandomForest, XGBoost 등으로 예측을 할 수 있을 텐데요. 저는 뭐 모르니까 그냥 Tensorflow로 인공지능을 만들어서 예측해 보겠습니다.
그래프를 보면, 딱히 강수량과 온도와 큰 관계가 없어 보이기도 합니다. 강수량이 적을 때도 저렇게 치솟는 게 보이니까요.
운영 체제: Windows 11 Home 21H2
데이터 분석 시작하기 6 (추정과 예측)
지금까지 기본적인 분석을 해보았는데요. 여기서 끝내면 아쉬우니 더 진행해 봅시다. 우리가 데이터를 분석하는 이유는 추정과 예측을 하기 위해서입니다. 저도 정확한 차이는 모르는데요. 추정은 기존의 데이터 범위에서 없는 자료를 분석해서 비어있는 공간을 채우는 것이고 예측은 기존 데이터의 범위를 벗어난 부분을 채우는 것이라고 저는 그냥 이해했는데요. 뭐 똑같은 거 아니냐 할 수 있는데 저도 모릅니다. 그냥 넘어가도록 하죠 헤헤.
LinearRegression을 쓰거나, RandomForest, XGBoost 등으로 예측을 할 수 있을 텐데요. 저는 뭐 모르니까 그냥 Tensorflow로 인공지능을 만들어서 예측해 보겠습니다.
그래프를 보면, 딱히 강수량과 온도와 큰 관계가 없어 보이기도 합니다. 강수량이 적을 때도 저렇게 치솟는 게 보이니까요.
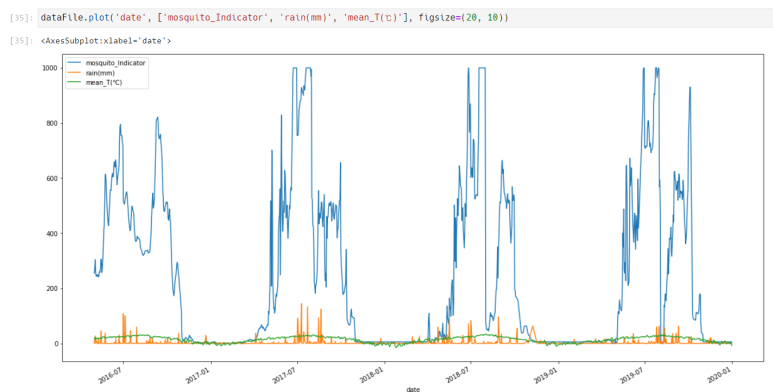
흠. 그래서 이런 고민은 그냥 인공지능에게 맡기기로 하죠. 알아서 잘
찾아주겠죠. 후훗.
필요 없는 column은 drop()으로 제거할 수 있습니다.
x에는 학습에 사용할 데이터를 모아놓고, y에는 x를 통해 예측할 값을 넣습니다.

시계열의 경우 시간이 숫자가 아닌 주기성을 지닌 값으로 변환해 줘야 합니다.
cosine과 sine을 사용하면 주기성을 지닌 데이터로 변환이 됩니다.

x_data에서 date는 cosine, sine으로 변경했기 때문에 date를 제거합니다.
x_data와 y_data는 아래와 같은 상태입니다.

사실 마음에 드는 데이터가 없네요. 예측이 잘 안될 거 같아요 저걸로 어떻게
예측이 되겠습니까...
자 일단 데이터를 나눠봅시다. 나누는 건 sklearn.model_selelection의
train_test_split을 사용합니다.
train_test_split() 괄호 안에는 학습 데이터, 결과 데이터, 비율, shuffle 기능,
random_state 숫자가 들어갑니다.

나눠진 크기를 봅시다. 75 : 25로 나눠졌을 겁니다.

학습은 PyCharm에서 진행하겠습니다. Jupyter에서 하는 건 뭔가 아쉬운 느낌이
듭니다.
각종 필요한 부분을 import 해줍니다.
random seed를 고정해 줍니다.

모델을 만들어 줍니다.
그냥 만들고 싶은 데로 만들면 됩니다.

모델을 만들고 학습을 지킵니다.

결과를 그래프로 그리기 위해서 함수를 정의하고 그려줍니다.

나름 비슷하게 나왔나요? 실패인 거 같아 보이긴 하네요. 그래도 실제 데이터가
올라갈 때 같이 올라가는 거 보이시나요? 있다 없다로 하면 그나마 정확도가 높을
거 같긴 한데... 정확히 예측하는 건 무리네요.

로스가 무려 25408.0005입니다.

데이터 자료가 강수량하고 온도만 있는데 무슨 수로 모기 지수를 알겠습니까. 만약
완벽한 예측을 하려면 더 근본적인 데이터가 추가로 필요할 거 같아 보이네요.
끝.
카테고리: Data Analysis






댓글
댓글 쓰기
궁금한 점은 댓글 달아주세요.
Comment if you have any questions.